
Content-Based Image Retrieval (Research project 2007-2008)
With the astounding number of digital images available, there is an increasing need to search image collections. Many systems such as Google and Flickr use text-based search, but the vast majority of photos (particularly family albums) have no text description available. Content-based image retrieval searches images using visual similarity, rather than text. In this research I investigated methods to improve the performance of image retrieval systems.
I devised an algorithm to automatically combine features using machine learning to improve retrieval accuracy. Perceptual characteristics (color and texture signatures) are extracted as a mathematical representation of images. My system determines the relative importance of color and texture for a given image query to optimize results.
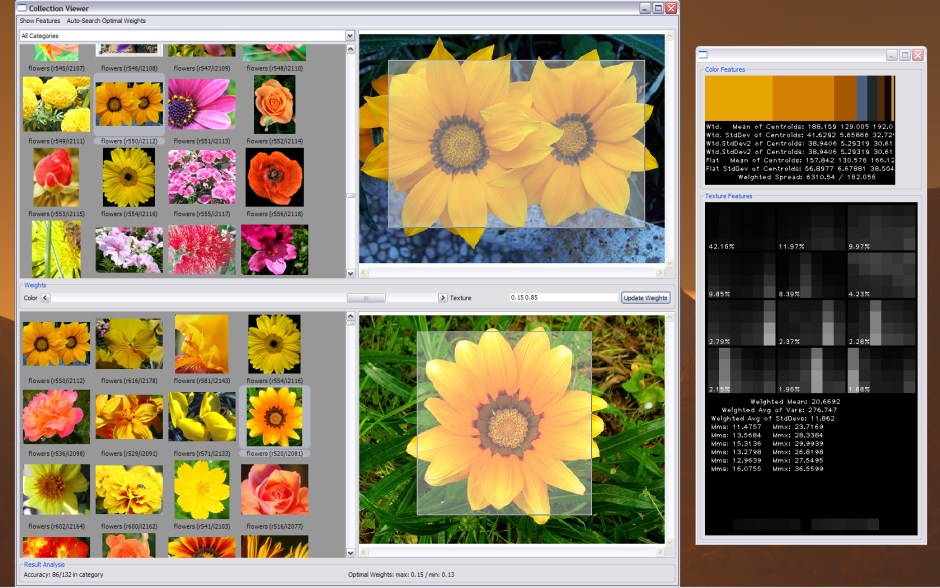
Tech Specs: Color signatures are extracted based on k-means clustering of Lab color space coordinates, and texture signatures are extracted using k-means clustering of Gabor filter dictionaries of 4 scales and 6 orientations. Signature dissimilarities are measured using the Earth Mover’s Distance, and integrated through normalized linear weighting. k-nearest neighbor supervised learning is used to predict weights based on statistical characteristics of color and texture signatures: “color spread” and “texture busyness”.
Comments